Sparql Droid – A Semantic Technology Application for the Android Platform
Friday, June 24th, 2011 The semantic technology concepts that comprise what is generally called the semantic web involve paradigm shifts in the ways that we represent data, organize information and compute results. Such shifts create opportunities and present challenges. The opportunities include easier correlation of decentralized information, flexible data relationships and reduced data storage entropy. The challenges include new data management technology, new syntaxes, and a new separation of data and its relationships.
The semantic technology concepts that comprise what is generally called the semantic web involve paradigm shifts in the ways that we represent data, organize information and compute results. Such shifts create opportunities and present challenges. The opportunities include easier correlation of decentralized information, flexible data relationships and reduced data storage entropy. The challenges include new data management technology, new syntaxes, and a new separation of data and its relationships.
I am a strong advocate of leveraging semantic technology. I believe that this new paradigms provide a more flexible basis for our journey to create meaningful, efficient and effective business automation solutions. However, one challenge that differentiates leveraging semantic technology from more common technology (such as relational databases) is the lack of mature tools supporting a business system infrastructure.
It will take a while for solid solutions to appear. Support for mainstream capabilities such as reporting, BI, workflow, application design and development that all leverage semantic technology are missing or weak at best. Again, this is an opportunity and a challenge. For those who enjoy creating computer software it presents a new world of possibilities. For those looking to leverage mature solutions in order to advance their business vision it will take investment and patience.
In parallel with the semantic paradigm we have an ever increasing focus on mobile-based solutions. Smart phones and tablet devices, focused on network connectivity as the enabler of value, rather than on-board storage and compute power, are becoming the standard tool for human-system interaction. As we design new solutions we must keep the mobile-accessible mantra in mind.
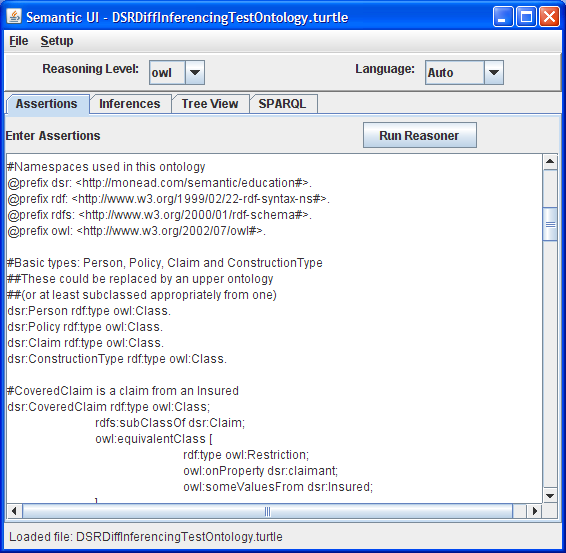
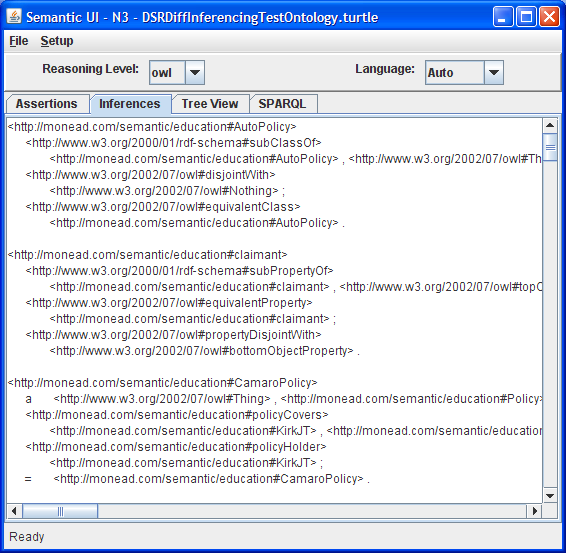
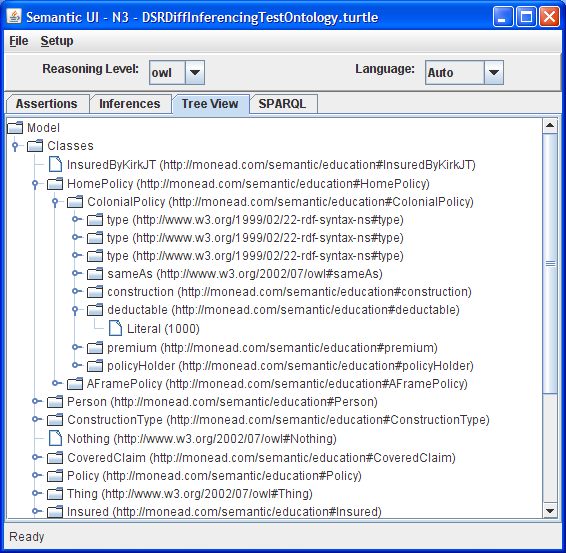
As part of my exploration of these two technologies, I’ve started working on a semantic technology mobile application called Sparql Droid. Built for the Android platform, my goal is a tool for exploring and mashing semantic data sources. As a small first-step I’ve leveraged the Androjena port of the Jena framework and created an application with some basic capabilities.