// JSON-LD for Wordpress Home, Articles and Author Pages. Written by Pete Wailes and Richard Baxter.
// See: http://builtvisible.com/implementing-json-ld-wordpress/
What separates today’s machine learning from human learning? One word: concepts.
“How so?” you might ask. To see what I mean, let’s start by looking at standard machine learning inputs and outputs. I’ll focus on supervised learning.
Supervised Machine Learning
Supervised machine learning is an approach where we start with a set of records. In each record, one field contains the correct answer, known as the target attribute. The other fields in the record contain related information, formally known as descriptive attributes. For example, we might have a set of measurements for flower petals and the flower’s name for each set of measures. We want the computer to learn how to identify different types of flowers. For those of you with machine learning experience, you’ll recognize the Iris data set as the inspiration for my example.
Supervised machine learning is similar to how we might teach children some set of math facts. We give them many examples of addition problems and answers. Over time we would like them to understand the mechanics of addition and solve novel problems. We have a similar goal with supervised learning. We want to give the computer lots of examples with the correct answers and have it figure out how to answer new problems.
Decision Trees
Table 1: Flower Data
Petal Length
Petal Width
Flower (Answer)
2
1.7
Rose
2.5
2.1
Rose
3.2
0.5
Daisy
3.6
0.6
Daisy
Figure 1: Example Decision Tree
We’ll begin looking at what the machine is learning using a basic supervised approach, decision trees. In this case, the computer looks at the correct answer, the target attribute. It uses the descriptive attributes in the record to create a decision that would use that record’s data to arrive at the correct result. In Table 1, there are four records. For each, there are two measurements for rose petals and daisy petals. The resulting decision tree might look like Figure 1.
This is a simple example, but the interesting point is that the computer is limited to making a decision using the data in the record. As discussed in my previous post, the text “Rose” doesn’t mean anything to the system. We could add additional data to the record, such as details about petal color and whether the stem has thorns. But the machine learning process won’t have that information available without explicitly adding it to the data. Since the computer doesn’t know what the text “Rose” means, it can’t incorporate other knowledge about roses into its decision tree.
This is a considerable hurdle in machine learning. As people learn new information, they build a knowledge base and apply it to new learning. That isn’t how these discreet learning processes work. And that limitation is imposed chiefly because the computer isn’t using concepts.
Neural Networks
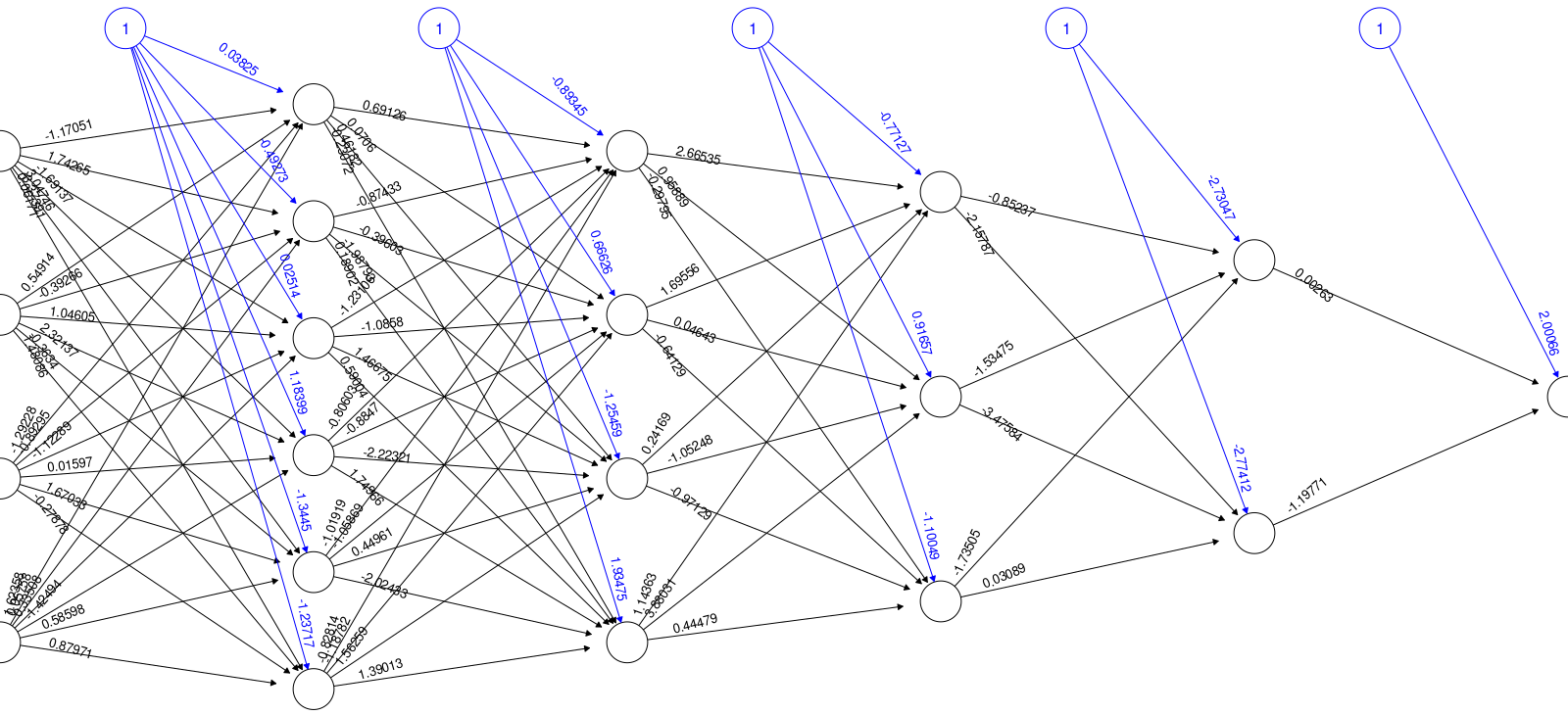
Let’s consider one other example of the disconnect between machine and human learning. Deep learning and neural networks get much attention when talking about machine learning and artificial intelligence. These work very differently from decision trees, but they start with the same premise when used for supervised learning, beginning with a set of records including descriptive features and a target feature. Then the neural network process diverges from decision tree induction. Neural network training uses an iterative process where each record is read, and an answer calculated. The answer is checked against the target attribute’s value. Based on whether the answer was correct, numeric weights are adjusted in the network to move toward the right solution.
Figure 2: Neural Network Example Showing Neurons and Weights
With this approach, the data is read many times. The network keeps adjusting the weights between its neurons until it arrives at correct answers or reaches some limit that we set to prevent the process from never finishing. The critical point is that the network develops a set of weights (see Figure 2). Suppose we assume a successful outcome, and the network has learned and can produce accurate answers to new problems. In that case, it can’t explain what it learned in a way that makes sense. Again, it isn’t learning concepts.
A well-known area of research using neural networks while needing to understand concepts is self-driving cars. There are several excellent articles describing how self-driving cars learn to “see.” These articles do a great job of introducing the process: https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503 and https://www.sciencedirect.com/science/article/pii/S0386111219301566 Note that the goal of these processes is to identify the objects around the vehicle, identify them as concepts. The process involves detecting the edges and shapes and arriving at a classification: person, sign, car, sidewalk, building.
Different from humans, expectations are not center stage for a self-driving car. We tend to use our experiences and expectations to anticipate situations. For example, suppose I’m driving behind a vehicle with some boxes precariously loaded on top. In that case, I’m going to be quite vigilant in keeping an eye on whether any of them start to fall and be ready to react long before it has hit the ground. This dimension of information comes from the interconnected nature of concepts in our brains.
Machine Learning Limitations for Business Modeling
Enough background for the moment. Let’s turn our attention to the application of machine learning to business problems. We’ve looked at two severe limitations in the way we frequently apply machine learning. First, without concepts, the computer must create models with minimal sets of descriptive attributes. We can increase the complexity of the data sets by investing more time and money. Second, since the model isn’t based on concepts, it isn’t easy to understand why it works the way it does. Let’s expand on why each of these limitations is a concern.
Considering point one, suppose the data used to learn is limited to the singular data set, which is the norm. Having few features could easily lead to a situation where the information needed to create an accurate model is unavailable. If we add lots of data fields, then we have the expense of managing a complex data set, which we know from years of data warehousing projects, is time-consuming, costly, and often incomplete.
Turning to point two if the model is learned and expressed separately from the concepts, we are unlikely to understand what learning is being described in the model. Even when a model is accurate, we generally want to know why. We seek an explanation for the answer. In some contexts, there could be legal ramifications for not correctly explaining the results from a model.
Both of these challenges are due to using a machine learning platform not based on concepts.
Let’s think about applying machine learning differently. Suppose we base machine learning on concepts and ensure that all learning is associated with, builds upon, and extends those. In that case, the learning platform could use all its existing knowledge when learning new things. The model could also be explained using our terminology since it uses our concepts as its foundation.
A couple of questions arise. One, what options might exist as a starting point for concepts? Two, can data be expressed so that conceptual meaning can be understood and extended by the computer? To answer that, we need to define better what is meant by a concept.
Next time: Representing Concepts
Let’s wrap up this installment. The discussion above greatly simplified the machine learning process. My goal was to highlight a couple of limitations that currently constrain machine learning without dealing with the core of the learning algorithms. Next post, I’ll pick up with the idea of basic concepts. Have a look at the Cyc data set as an example. I’ll also explore the representation of concepts in a machine learning context.