Archive for the ‘Tools and Applications’ Category
Wednesday, August 18th, 2010
As a way to work with semantic web concepts, including asserting triples, seeing the resulting inferences and also leveraging SPARQL, I have needed a GUI. In this post I’ll describe a very basic tool that I have created and released that allows a user to interact with a semantic model.
My objectives for this first GUI were basic:
- Support input of a set of triples in any format that Jena supports (e.g. REF/XML, N3, N-Triples and Turtle)
- See the inferences that result for a set of assertions
- Create a tree view of the ontology
- Make it easy to use SPARQL queries with the model
- Allow the resulting model to be written to a file, again using any format supported by Jena
Here are some screen shots of the application. Explanations of the tabs are then provided.
-
-
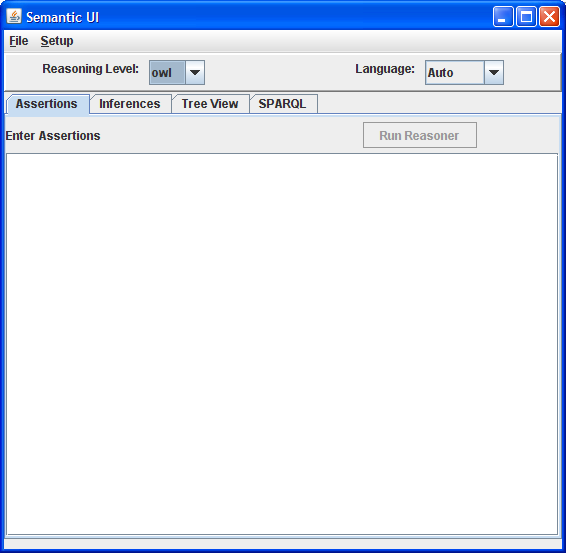
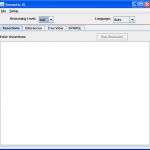
Initial View: Appearance at startup. The reasoner cannot be run until there is text in the assertions text area.
-
-
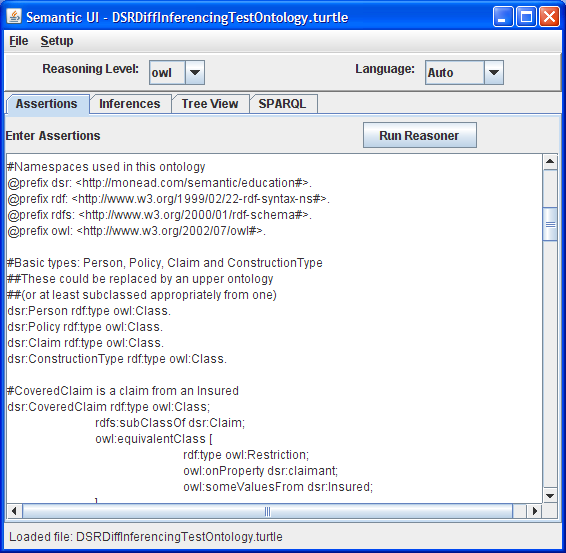
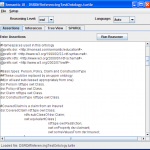
Assertions Tab Populated: The assertions tab is shown populated. The Run Reasoner button is then used to run the reasoner and create an in-memory model that can be saved to disk or explored using SPARQL.
-
-
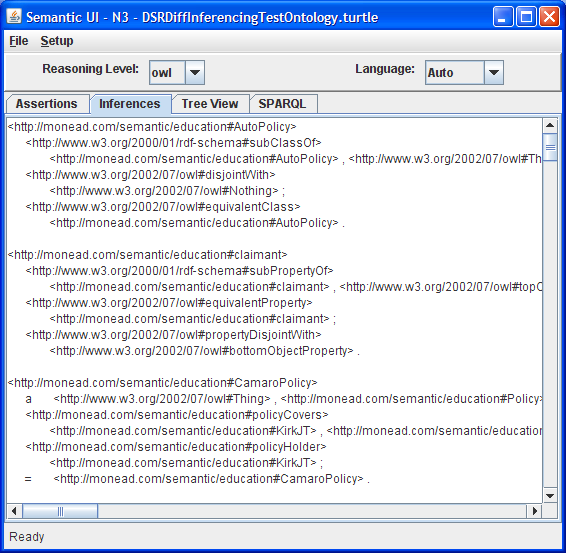
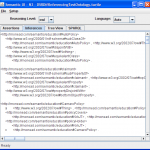
Inferences Tab: Once the reasoner has been run successfully (e.g. legal set of assertons entered on the Assertions tab and the Run Reasoner button used), any inferences will be displayed on this tab.
-
-
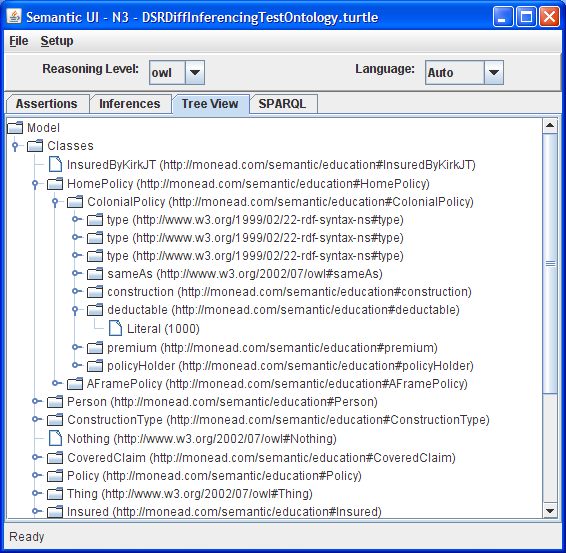
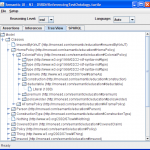
Tree View Tab: Once the reasoner has been run successfully (e.g. legal set of assertons entered on the Assertions tab and the Run Reasoner button used), the model (asserted and inferred) will be shown as a tree structure based on class.
-
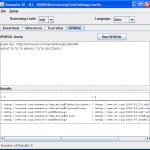
-
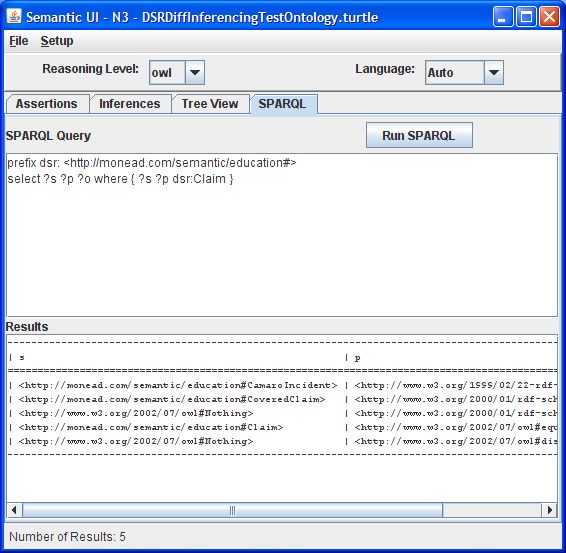
SPARQL Tab: Execute SPARQL queries against the model
The program provides each feature in a very basic way. On the Assertions tab a text area is used for entering assertions. The user may also load a text file containing assertions using the File|Open menu item. Once the assertions are entered, a button is enabled that allows the reasoner to process the assertions. The reasoner level is controlled by the user from a drop down.
(more…)
Tags: Information Systems, linkedin, ontology, open source, semantic web, semantics
Posted in Information Systems, Java, Semantic Web, Tools and Applications | No Comments »
Thursday, August 5th, 2010
In an earlier blog entry I discussed the potential reduction in refactoring effort if our data is represented as RDF triples rather than relational structures. As a way to give myself easy access to RDF data and to work more with semantic web tool features I have created a program to export relational data to RDF.
The program is really a proof-of-concept. It takes a SQL query and converts the resulting rows into assertions of triples. The approach is simple: given a SQL statement and a chosen primary key column (PK) to represent the instance for the exported data, assert triples with the primary key column value as the subject, the column names as the predicates and the non-PK column values as the objects.
Here is a brief sample taken from the documentation accompanying the code.
- Given a table named people with the following columns and rows:
id name age
-- ---- ---
1 Fred 20
2 Martha 25
- And a query of: select id, name, age from people
- And the primary key column set to: id
- Then the asserted triples (shown using Turtle and skipping prefixes) will be:
dsr:PK_1
a owl:Thing , dsr:RdbData ;
rdfs:label "1" ;
dsr:name "Fred" ;
dsr:age "20" .
dsr:PK_2
a owl:Thing , dsr:RdbData ;
rdfs:label "2" ;
dsr:name "Martha" ;
dsr:age "25" .
You can see that the approach represents a quick way to convert the data.
(more…)
Tags: data, Information Systems, Java, linkedin, ontology, open source, programming, semantic web, semantics
Posted in Information Systems, Java, Semantic Web, Software Composition, Software Development, Tools and Applications | 1 Comment »
Monday, July 26th, 2010
InformationWeek Analytics (http://analytics.informationweek.com/index) invited me to write about the subject of process automation. The article, part of their series covering application architectures, was released in July of this year. It provided an opportunity for me to articulate the key components that are required to succeed in the automation of business processes.
Both the business and IT are positioned to make-or-break the use of process automation tools and techniques. The business must redefine its processes and operational rules so that work may be automated. IT must provide the infrastructure and expertise to leverage the tools of the process automation trade.
Starting with the business there must be clearly defined processes by which work gets done. Each process must be documented, including the points where decisions are made. The rules for those decisions must then be documented. Repetitive, low-value and low-risk decisions are immediate candidates for automation.
A key value point that must be reached in order to extract sustainable and meaningful value from process automation is measured in Straight Through Processing (STP). STP requires that work arrive from a third-party and be automatically processed; returning a final decision and necessary output (letter, claim payment, etc.) without a person being involved in handling the work.
Most businesses begin using process automation tools without achieving any significant STP rate. This is fine as a starting point so long as the business reviews the manual work, identifies groupings of work, focuses on the largest groupings (large may be based on manual effort, cost or simple volume) and looks to automate the decisions surrounding that group of work. As STP is achieved for some work, the review process continues as more and more types of work are targeted for automation.
The end goal of process automation is to have people involved in truly exceptional, high-value, high-risk, business decisions. The business benefits by having people attend to items that truly matter rather than dealing with a large amount background noise that lowers productivity, morale and client satisfaction.
All of this is great in theory but requires an information technology infrastructure that can meet these business objectives.
(more…)
Tags: BPM, business rules, enterprise applications, Information Systems, linkedin, Process Automation, process modeling, system integration, web services, Workflow
Posted in Architecture, Information Systems, Software Development, Tools and Applications | No Comments »
Saturday, June 5th, 2010
I have create my first slightly interesting, to me anyway, program that uses some semantic web technology. Of course I’ll look back on this in a year and cringe, but for now it represents my understanding of a small set of features from Jena and Pellet.
The basis for the program is an example program that is described in Hebler, Fischer et al’s book “Semantic Web Programming” (ISBN: 047041801X). The intent of the program is to load an ontology into three models, each running a different level of reasoner (RDF, RDFS and OWL) and output the resulting assertions (triples).
I made a couple of changes to the book’s sample’s approach. First I allow any supported input file format to be automatically loaded (you don’t have to tell the program what format is being used). Second, I report the actual differences between the models rather than just showing all the resulting triples.
As I worked on the code, which is currently housed in one uber-class (that’ll have to be refactored!), I realized that there will be lots of reusable “plumbing” code that comes with this type of work. Setting up models with various reasoners, loading ontologies, reporting triples, interfacing to triple stores, and so on will become nuisance code to write.
Libraries like Jena help, but they abstract at a low level. I want a semantic workbench that makes playing with the various libraries and frameworks easy. To that end I’ve created a Sourceforge project called “Semantic Workbench“.
I intend for the Semantic Workbench to provide a GUI environment for manipulating semantic web technologies. Developers and power users would be able to use such a tool to test ontologies, try various reasoners and validate queries. Developers could use the workbench’s source code to understand how to utilize frameworks like Jena or reasoner APIs like that of Pellet.
I invite other interested people to join the Sourceforge project. The project’s URL is: http://semanticwb.sourceforge.net/
On the data side, in order to have a rich semantic test data set to utilize, I’ve started an ontology that I hope to grow into an interesting example. I’m using the insurance industry as its basis. The rules around insurance and the variety of concepts should provide a rich set of classes, attributes and relationships for modeling. My first version of this example ontology is included with the sample program.
Finally, I’ve added a semantic web section to my website where I’ll maintain links to useful information I find as well as sample code or files that I think might be of interest to other developers. I’ve placed the sample program and ontology described earlier in this post on that page along with links to a variety of resources.
My site’s semantic web page’s URL is: http://monead.com/semantic/
The URL for the page describing the sample program is: http://monead.com/semantic/proj_diffinferencing.html
Tags: Information Systems, Java, linkedin, ontology, open source, programming, semantic web, semantics, system integration
Posted in Information Systems, Java, Semantic Web, Software Composition, Software Development, Tools and Applications | 1 Comment »
Wednesday, May 12th, 2010
One of the aspects of agile software development that may lead to significant angst is the database. Unlike refactoring code, the refactoring of the database schema involves a key constraint – state! A developer may rearrange code to his or her heart’s content with little worry since the program will start with a blank slate when execution begins. However, the database “remembers.” If one accepts that each iteration of an agile process produces a production release then the stored data can’t be deleted as part of the next iteration.
The refactoring of a database becomes less and less trivial as project development continues. While developers have IDE’s to refactor code, change packages, and alter build targets, there are few tools for refactoring databases.
My definition of a database refactoring tool is one that assists the database developer by remembering the database transformation steps and storing them as part of the project – e.g. part of the build process. This includes both the schema changes and data transformations. Remember that the entire team will need to reproduce these steps on local copies of the database. It must be as easy to incorporate a peer’s database schema changes, without losing data, as it is to incorporate the code changes.
These same data-centric complexities exist in waterfall approaches when going from one version to the next. Whenever the database structure needs to change, a path to migrate the data has to be defined. That transformation definition must become part of the project’s artifacts so that the data migration for the new version is supported as the program moves between environments (test, QA, load test, integrated test, and production). Also, the database transformation steps must be automated and reversible!
That last point, the ability to rollback, is a key part of any rollout plan. We must be able to back out changes. It may be that the approach to a rollback is to create a full database backup before implementing the update, but that assumption must be documented and vetted (e.g. the approach of a full backup to support the rollback strategy may not be reasonable in all cases).
This database refactoring issue becomes very tricky when dealing with multiple versions of an application. The transformation of the database schema and data must be done in a defined order. As more and more data is stored, the process consumes more storage and processing resources. This is the ETL side-effect of any system upgrade. Its impact is simply felt more often (e.g. potentially during each iteration) in an agile project.
As part of exploring semantic technology, I am interested in contrasting this to a database that consists of RDF triples. The semantic relationships of data do not change as often (if at all) as the relational constructs. Many times we refactor a relational database as we discover concepts that require one-to-many or many-to-many relationships.
Is an RDF triple-based database easier to refactor than a relational database? Is there something about the use of RDF triples that reduces the likelihood of a multiplicity change leading to a structural change in the data? If so, using RDF as the data format could be a technique that simplifies the development of applications. For now, let’s take a high-level look at a refactoring use case.
(more…)
Tags: agile development, efficient coding, enterprise applications, enterprise systems, Information Systems, linkedin, ontology, refactoring, semantic web, semantics, system integration
Posted in Architecture, Information Systems, Semantic Web, Software Composition, Software Development, Tools and Applications | 1 Comment »
Sunday, May 9th, 2010
Last week I had the pleasure of attending Semantic Arts’ training class entitled, “Designing and Building Business Ontologies.” The course, led by Dave McComb and Simon Robe, provided an excellent introduction to semantic technologies and tools as well as coverage of ontological best practices. I thoroughly enjoyed the 4-day class and achieved my principle goals in attending; namely to understand the semantic web landscape, including technologies such as RDF, RDFS, OWL, SPARQL, as well as the current state of tools and products in this space.
Both Dave and Simon have a deep understanding of this subject area. They also work with clients using this technology so they bring real-world examples of where the technology shines and where it has limitations. I recommend this class to anyone who is seeking to reach a baseline understanding of semantic technologies and ontology strategies.
Why am I so interested in semantic web technology? I am convinced that structuring information such that it can be consumed by systems, in ways more automated than current data storage and association techniques allow, is required in order to achieve any meaningful advancement in the field of information technology (IT). Whether wiring together web services or setting up ETL jobs to create data marts, too much IT energy is wasted on repeatedly integrating data sources; essentially manually wiring together related information in the absence of the computer being able to wire it together autonomously!
(more…)
Tags: efficient coding, enterprise applications, enterprise systems, Information Systems, linkedin, ontology, Public Data, semantic web, semantics, system integration, web services
Posted in Architecture, Information Systems, Public Data, Software Composition, Software Development, Tools and Applications | 1 Comment »
Wednesday, April 28th, 2010
This is a follow-up to my previous entry regarding full disk encryption (see: http://monead.com/blog/?p=319). In this entry I’ll look at Blue Slate’s experience with rolling out full disk encryption company-wide.
Blue Slate began experimenting with full disk encryption in 2008. I was actually the first user at our company to have a completely encrypted disk. My biggest surprise was the lack of noticeable impact on system performance. My machine (Gateway M680) was running Windows XP and I had 2GB of RAM and a similarly-sized swap space. Beyond a lot of programming work I do video and audio editing. I did not notice significant impact on editing and rendering of such projects.
Later in 2008, we launched a proof of concept (POC) project involving team members from across the company (technical and non-technical users). This test group utilized laptops with fully encrypted drives for several months. We wanted to assure that we would not have problems with the various software packages that we use. During this time we went through XP service pack releases, major software version upgrades and even a switch of our antivirus solution. We had no reports of encryption-related issues from any of the participants.
By 2009 we were focused on leveraging full disk encryption on every non-server computer in the company. It took some time due to two constraints.
First, we needed to rollout a company-wide backup solution (as mentioned in my previous post on full disk encryption, recovery of files from a corrupted encrypted device is nearly impossible). Second, we needed to work through a variety of scheduling conflicts (we needed physical access to each machine to setup the encryption product) across our decentralized workforce.
(more…)
Tags: data security, disk encryption, encryption, enterprise systems, full disk encryption, linkedin, mitigation, Security, vulnerability
Posted in Information Systems, Security, Tools and Applications | No Comments »
Thursday, February 18th, 2010
During the past several months I’ve had an interesting experience working with Brainbench. As you may know, Brainbench (a part of Previsor) offers assessment tests and certifications across a wide range of subjects. They cover many technical and non-technical areas. I have taken Brainbench exams myself and I have seen them used as a component within a hiring process. However, I did not understand how these exams were created.
 That mystery ended for me late last year when I received an email looking for technologists to assist in validating a new exam that Brainbench was creating to cover Spring version 2.5. Being curious about the test creation process I applied for the advertised validator role. I was pleasantly surprised when they contacted me with an offer for the role of test author instead.
That mystery ended for me late last year when I received an email looking for technologists to assist in validating a new exam that Brainbench was creating to cover Spring version 2.5. Being curious about the test creation process I applied for the advertised validator role. I was pleasantly surprised when they contacted me with an offer for the role of test author instead.
I will not delve into Brainbench’s specific exam creation approach since I assume it is proprietary and want to be sure I respect their intellectual property. What I found was a very well-planned and thorough process. Having a background in education and a strong interest in teaching and mentoring, I know the challenge of creating a meaningful assessment. In the case of their approach, they focus on an accurate and well-considered exam.
I believe that I am quite knowledgeable regarding Spring. I have used many of its features for work and personal projects. The philosophies supported by the product (encouraged, not prescribed) address many areas of coding that help reduce clutter, decouple implementations, and simplify testing. As a true fan of Spring’s feature set, I found it challenging to decide which aspects were most important when assessing an individual’s knowledge of the overall framework. (more…)
Tags: assessment, Brainbench, education, skill testing, Spring
Posted in Java, Software Development, Tools and Applications | No Comments »
Friday, November 6th, 2009
With the vendors gone the main hall seemed spacious during the morning keynote and lunch time presentations. James Taylor [of "Smart (Enough) Systems" fame] delivered the keynote address. He always has interesting insights regarding the state of affairs for agile systems design, both leveraging automated decisioning and workflow processes.
James made the point that systems need to be more agile given higher levels of uncertainty with which our businesses deal. The need to adjust and react is more critical as our business strategies and goals flex to the changing environment. Essentially he seemed to be saying that businesses should not reduce their efforts to be agile during this economic downturn. Rather, it is more important to increase agility in order to respond quickly to shifting opportunities.
Following the keynote I attended Brian Dickinson’s session titled, “Business Event Driven Enterprises Rule!” The description of the session in the conference guide had caught my attention since it mentioned “event partitioning” which was a phrase I had not heard used in terms of designing automated solutions for businesses.
I was glad that I went. Brian was an energetic speaker! It was clear that he was deeply committed and passionate about focusing on events rather than functionality when considering process automation. The hour-long session flew by and it was apparent that we hadn’t made a dent in what he really wanted to communicate.
Brian was kind enough to give attendees a copy of his book, “Creating Customer Focused Organizations” which I hope expands on the premise of his presentation today. Although quite natural as a design paradigm when building event-driven UI’s and multi-threaded applications, I have not spent time focused on events when designing the business and database tiers of applications. For me, the first step of working with his central tenants will be to try applying them, at least in a small way, on my next architecture project. (more…)
Tags: business rules, enterprise systems, Information Systems, system integration
Posted in Architecture, Information Systems, Software Development, Tools and Applications | No Comments »
Thursday, November 5th, 2009
The second day of the BRF is typically the most active. People are arriving throughout day 1 and start heading out on day 3. I’m attending RuleML, which follows on the heels of the BRF, so I’ll be here for all if it.
The morning keynote was delivered by Stephen Hendrick (IDC). His presentation was titled, “BRMS at a Cross Roads: the Next Five Years.” It was interesting hearing his vision of how BRMS vendors will need to position their offerings in order to be relevant for the future needs of businesses.
I did find myself wondering whether his vision was somewhat off in terms of timing. The move to offer unified (or at least integrated) solutions based on traditional BRMS, Complex Event Processing, Data Transformation and Analytics seemed well beyond where I find many clients are in terms of leveraging the existing BRMS capabilities.
Between discussions with attendees and work on projects for which Blue Slate’s customers hire us, the current state of affairs seems to be more about understanding how to begin using a BRMS. I find many clients are just getting effective governance, rules harvesting and infrastructure support for BRMS integration started. Discussions surrounding more complex functionality are premature for these organizations.
As usual, there were many competing sessions throughout the day that I wanted to attend. I had to choose between these and spending some in-depth time with a few of the vendors. One product that I really wanted to get a look at was JBoss Rules (Red Hat).
Similar to most Red Hat offerings there are free and fee-based versions of the product. Also, as is typical between the two versions, the fee-based version is aimed at enterprises that do not want to deal with experimental or beta aspects of the product, instead preferring a more formal process of periodic production-worthy upgrades. The fee-based offering also gets you support, beyond the user groups available to users of the free version.
The naming of the two versions is not clear to me. I believe that the fee-based version is called JBoss Rules while the free download is called JBoss Drools, owning to the fact that Red Hat used drools as the basis for its rule engine offering. The Drools suite includes BPM, BRM and Event Processing components. My principle focus was the BRMS to start.
The premier open source rules offering (my opinion) has come a long way since I last tried it over a year ago. The feature set includes a version control repository for the rules, somewhat user-friendly rule editing forms and a test harness. Work is underway to support templating for rules, which is vital for creating rules that can be maintained easily by business users. I will be downloading and working with this rule engine again shortly! (more…)
Tags: business rules, Information Systems, system integration
Posted in Architecture, Information Systems, Software Development, Tools and Applications | No Comments »