Posts Tagged ‘Information Systems’
Wednesday, September 15th, 2010
For years we’ve been hearing about the importance of Enterprise Architecture (EA) frameworks. The messages from a variety of sources such as Zachman, TOGAF, HL7 and others is that businesses have to do an incredible amount of planning, documenting, discussing, benchmarking, evaluation, (feel free to insert more up-front work here) before they will have a good basis to implement their IT infrastructure. Once implemented all the documentation must be maintained, updated, verified, expanded, improved, (once again, insert more ongoing documentation management work here). Oh, by the way, your company may want some actual IT work aligned with its core operations to be accomplished as part of all this investment. I don’t believe such a dependency is covered well in any of the EA material.
I have always struggled with these EA frameworks. Their overhead seems completely unreasonable. I agree that planning the IT infrastructure is necessary. This is no different than planning any sort of infrastructure. Where I get uncomfortable is in the incredible depth and precision these frameworks want to utilize. IT infrastructures do not have the complete inflexibility of buildings or roads. Computer systems have a malleability that allows them to be adapted over time, particularly if the adjustments are in line with the core design.
Before anyone concludes that I do not believe in having a defined IT architecture let me assure you that I consistently advocate having a well-planned and documented IT architecture to support the enterprise. A happenstance of randomly chosen and deployed technologies and integrations is inefficient and expensive. I just believe that such planning and documentation do not need to be anywhere near as heavyweight as the classical EA frameworks suggest.
So you can imagine, based on this brief background, that I was not particularly surprised when the Zachman lawsuit and subsequent response from Stan Locke (Metadata Systems Software) failed to stop EA progress within Blue Slate or any of our clients. I’m not interested in rehashing what a variety of blogs have already discussed regarding the lawsuit. My interest is simply that there may be more vapor in the value of these large frameworks than their purveyors would suggest.
(more…)
Tags: architecture, EA, EA framework, enterprise architecture, enterprise systems, Information Systems, linkedin
Posted in Architecture, Information Systems | 2 Comments »
Monday, August 23rd, 2010
SQL Injection is commonly given as a root cause when news sites report about stolen data. Here are a few recent headlines for articles describing data loss related to SQL injection: Hackers steal customer data by accessing supermarket database1, Hacker swipes details of 4m Pirate Bay users2, and Mass Web Attack Hits Wall Street Journal, Jerusalem Post3. I understand that SQL injection is prevalent; I just don’t understand why developers continue to write code that offers this avenue to attackers.
From my point of view SQL injection is very well understood and has been for many years. There is no excuse for a programmer to create code that allows for such an attack to succeed. For me this issue falls squarely on the shoulders of people writing applications. If you do not understand the mechanics of SQL injection and don’t know how to effectively prevent it then you shouldn’t be writing software.
The mechanics of SQL injection are very simple. If input from outside an application is incorporated into a SQL statement as literal text, a potential SQL injection vulnerability is created. Specifically, if a parameter value is retrieved from user input and appended into a SQL statement which is then passed on to the RDBMS, the parameter’s value can be set by an attacker to alter the meaning of the original SQL statement.
Note that this attack is not difficult to engineer, complicated to execute or a risk only with web-based applications. There are tools to quickly locate and attack vulnerable applications. Also note that using encrypted channels (e.g. HTTPS) does nothing to prevent this attack. The issue is not related to encrypting the data in transit, rather, it is about keeping the untrusted data away from the backend RDMBS’ interpretation environment.
Here is a simple example of how SQL injection works. Assume we have an application that accepts a last name which will be used to search a database for contact information. The program takes the input, stores it in a variable called lastName, and creates a query:
String sql = "select * from contact_info where lname = '" + lastName + "'";
Now, if an attacker tries the input of: ‘ or 1=1 or ’2′=’
It will create a SQL statement of:
select * from contact_info where lname = '' or 1=1 or '2'=''
This is a legal SQL statement and will retrieve all the rows from the contact_info table. This might expose a lot of data or possibly crash the environment (a denial of service attack). In any case, using other SQL keywords, particularly UNION, the attacker can now explore the database, including other tables and schemas.
(more…)
Tags: application security, data security, Information Systems, Java, linkedin, mitigation, programming, Security, SQL injection, vulnerability
Posted in Information Systems, Java, Security, Software Development, Software Security | No Comments »
Wednesday, August 18th, 2010
As a way to work with semantic web concepts, including asserting triples, seeing the resulting inferences and also leveraging SPARQL, I have needed a GUI. In this post I’ll describe a very basic tool that I have created and released that allows a user to interact with a semantic model.
My objectives for this first GUI were basic:
- Support input of a set of triples in any format that Jena supports (e.g. REF/XML, N3, N-Triples and Turtle)
- See the inferences that result for a set of assertions
- Create a tree view of the ontology
- Make it easy to use SPARQL queries with the model
- Allow the resulting model to be written to a file, again using any format supported by Jena
Here are some screen shots of the application. Explanations of the tabs are then provided.
-
-
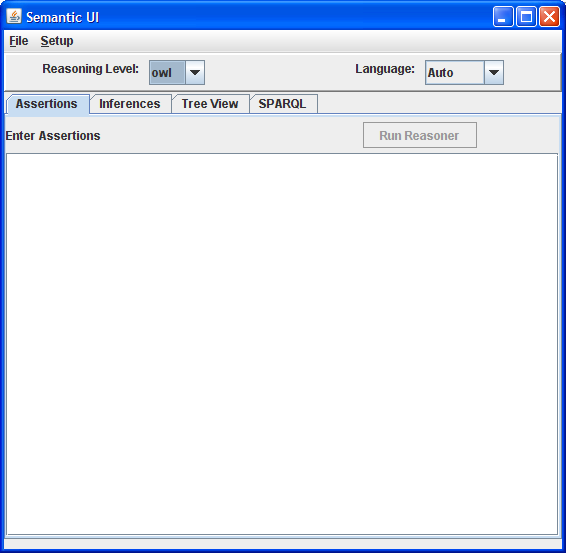
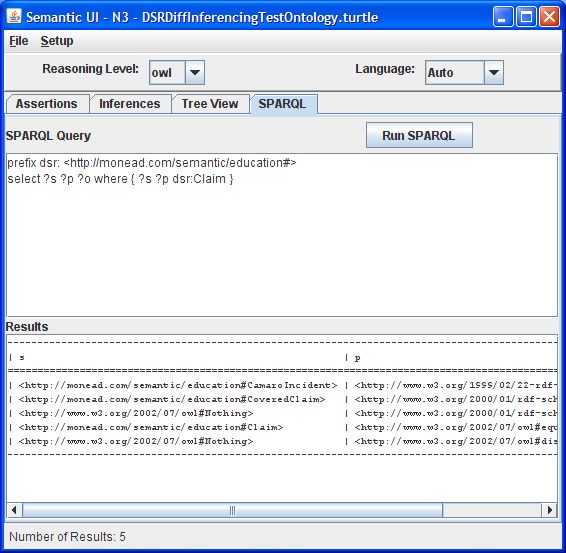
Initial View: Appearance at startup. The reasoner cannot be run until there is text in the assertions text area.
-
-
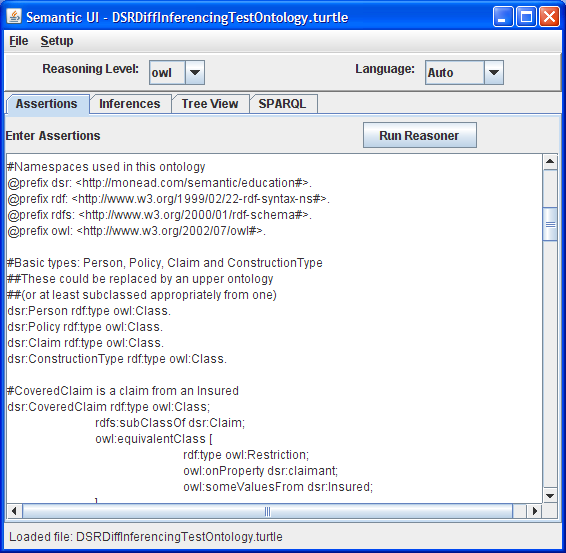
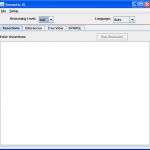
Assertions Tab Populated: The assertions tab is shown populated. The Run Reasoner button is then used to run the reasoner and create an in-memory model that can be saved to disk or explored using SPARQL.
-
-
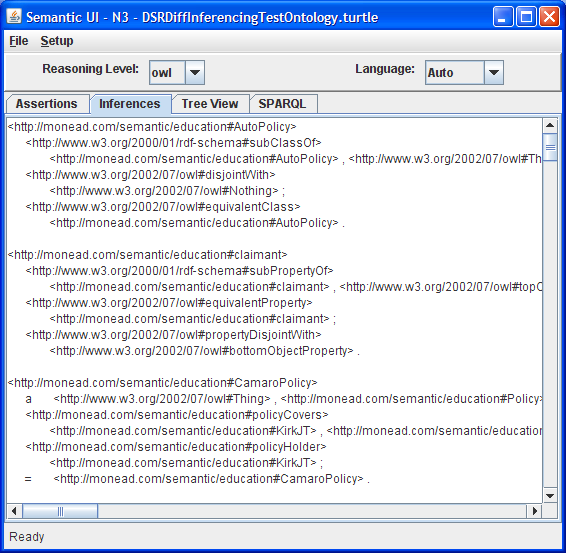
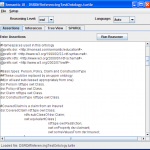
Inferences Tab: Once the reasoner has been run successfully (e.g. legal set of assertons entered on the Assertions tab and the Run Reasoner button used), any inferences will be displayed on this tab.
-
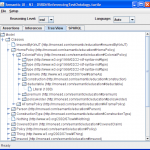
-
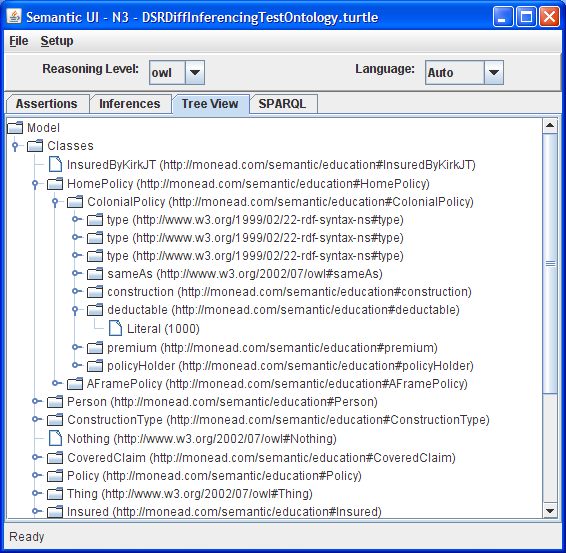
Tree View Tab: Once the reasoner has been run successfully (e.g. legal set of assertons entered on the Assertions tab and the Run Reasoner button used), the model (asserted and inferred) will be shown as a tree structure based on class.
-
-
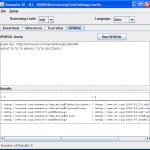
SPARQL Tab: Execute SPARQL queries against the model
The program provides each feature in a very basic way. On the Assertions tab a text area is used for entering assertions. The user may also load a text file containing assertions using the File|Open menu item. Once the assertions are entered, a button is enabled that allows the reasoner to process the assertions. The reasoner level is controlled by the user from a drop down.
(more…)
Tags: Information Systems, linkedin, ontology, open source, semantic web, semantics
Posted in Information Systems, Java, Semantic Web, Tools and Applications | No Comments »
Thursday, August 5th, 2010
In an earlier blog entry I discussed the potential reduction in refactoring effort if our data is represented as RDF triples rather than relational structures. As a way to give myself easy access to RDF data and to work more with semantic web tool features I have created a program to export relational data to RDF.
The program is really a proof-of-concept. It takes a SQL query and converts the resulting rows into assertions of triples. The approach is simple: given a SQL statement and a chosen primary key column (PK) to represent the instance for the exported data, assert triples with the primary key column value as the subject, the column names as the predicates and the non-PK column values as the objects.
Here is a brief sample taken from the documentation accompanying the code.
- Given a table named people with the following columns and rows:
id name age
-- ---- ---
1 Fred 20
2 Martha 25
- And a query of: select id, name, age from people
- And the primary key column set to: id
- Then the asserted triples (shown using Turtle and skipping prefixes) will be:
dsr:PK_1
a owl:Thing , dsr:RdbData ;
rdfs:label "1" ;
dsr:name "Fred" ;
dsr:age "20" .
dsr:PK_2
a owl:Thing , dsr:RdbData ;
rdfs:label "2" ;
dsr:name "Martha" ;
dsr:age "25" .
You can see that the approach represents a quick way to convert the data.
(more…)
Tags: data, Information Systems, Java, linkedin, ontology, open source, programming, semantic web, semantics
Posted in Information Systems, Java, Semantic Web, Software Composition, Software Development, Tools and Applications | 1 Comment »
Monday, July 26th, 2010
InformationWeek Analytics (http://analytics.informationweek.com/index) invited me to write about the subject of process automation. The article, part of their series covering application architectures, was released in July of this year. It provided an opportunity for me to articulate the key components that are required to succeed in the automation of business processes.
Both the business and IT are positioned to make-or-break the use of process automation tools and techniques. The business must redefine its processes and operational rules so that work may be automated. IT must provide the infrastructure and expertise to leverage the tools of the process automation trade.
Starting with the business there must be clearly defined processes by which work gets done. Each process must be documented, including the points where decisions are made. The rules for those decisions must then be documented. Repetitive, low-value and low-risk decisions are immediate candidates for automation.
A key value point that must be reached in order to extract sustainable and meaningful value from process automation is measured in Straight Through Processing (STP). STP requires that work arrive from a third-party and be automatically processed; returning a final decision and necessary output (letter, claim payment, etc.) without a person being involved in handling the work.
Most businesses begin using process automation tools without achieving any significant STP rate. This is fine as a starting point so long as the business reviews the manual work, identifies groupings of work, focuses on the largest groupings (large may be based on manual effort, cost or simple volume) and looks to automate the decisions surrounding that group of work. As STP is achieved for some work, the review process continues as more and more types of work are targeted for automation.
The end goal of process automation is to have people involved in truly exceptional, high-value, high-risk, business decisions. The business benefits by having people attend to items that truly matter rather than dealing with a large amount background noise that lowers productivity, morale and client satisfaction.
All of this is great in theory but requires an information technology infrastructure that can meet these business objectives.
(more…)
Tags: BPM, business rules, enterprise applications, Information Systems, linkedin, Process Automation, process modeling, system integration, web services, Workflow
Posted in Architecture, Information Systems, Software Development, Tools and Applications | No Comments »
Saturday, June 5th, 2010
I have create my first slightly interesting, to me anyway, program that uses some semantic web technology. Of course I’ll look back on this in a year and cringe, but for now it represents my understanding of a small set of features from Jena and Pellet.
The basis for the program is an example program that is described in Hebler, Fischer et al’s book “Semantic Web Programming” (ISBN: 047041801X). The intent of the program is to load an ontology into three models, each running a different level of reasoner (RDF, RDFS and OWL) and output the resulting assertions (triples).
I made a couple of changes to the book’s sample’s approach. First I allow any supported input file format to be automatically loaded (you don’t have to tell the program what format is being used). Second, I report the actual differences between the models rather than just showing all the resulting triples.
As I worked on the code, which is currently housed in one uber-class (that’ll have to be refactored!), I realized that there will be lots of reusable “plumbing” code that comes with this type of work. Setting up models with various reasoners, loading ontologies, reporting triples, interfacing to triple stores, and so on will become nuisance code to write.
Libraries like Jena help, but they abstract at a low level. I want a semantic workbench that makes playing with the various libraries and frameworks easy. To that end I’ve created a Sourceforge project called “Semantic Workbench“.
I intend for the Semantic Workbench to provide a GUI environment for manipulating semantic web technologies. Developers and power users would be able to use such a tool to test ontologies, try various reasoners and validate queries. Developers could use the workbench’s source code to understand how to utilize frameworks like Jena or reasoner APIs like that of Pellet.
I invite other interested people to join the Sourceforge project. The project’s URL is: http://semanticwb.sourceforge.net/
On the data side, in order to have a rich semantic test data set to utilize, I’ve started an ontology that I hope to grow into an interesting example. I’m using the insurance industry as its basis. The rules around insurance and the variety of concepts should provide a rich set of classes, attributes and relationships for modeling. My first version of this example ontology is included with the sample program.
Finally, I’ve added a semantic web section to my website where I’ll maintain links to useful information I find as well as sample code or files that I think might be of interest to other developers. I’ve placed the sample program and ontology described earlier in this post on that page along with links to a variety of resources.
My site’s semantic web page’s URL is: http://monead.com/semantic/
The URL for the page describing the sample program is: http://monead.com/semantic/proj_diffinferencing.html
Tags: Information Systems, Java, linkedin, ontology, open source, programming, semantic web, semantics, system integration
Posted in Information Systems, Java, Semantic Web, Software Composition, Software Development, Tools and Applications | 1 Comment »
Wednesday, May 12th, 2010
One of the aspects of agile software development that may lead to significant angst is the database. Unlike refactoring code, the refactoring of the database schema involves a key constraint – state! A developer may rearrange code to his or her heart’s content with little worry since the program will start with a blank slate when execution begins. However, the database “remembers.” If one accepts that each iteration of an agile process produces a production release then the stored data can’t be deleted as part of the next iteration.
The refactoring of a database becomes less and less trivial as project development continues. While developers have IDE’s to refactor code, change packages, and alter build targets, there are few tools for refactoring databases.
My definition of a database refactoring tool is one that assists the database developer by remembering the database transformation steps and storing them as part of the project – e.g. part of the build process. This includes both the schema changes and data transformations. Remember that the entire team will need to reproduce these steps on local copies of the database. It must be as easy to incorporate a peer’s database schema changes, without losing data, as it is to incorporate the code changes.
These same data-centric complexities exist in waterfall approaches when going from one version to the next. Whenever the database structure needs to change, a path to migrate the data has to be defined. That transformation definition must become part of the project’s artifacts so that the data migration for the new version is supported as the program moves between environments (test, QA, load test, integrated test, and production). Also, the database transformation steps must be automated and reversible!
That last point, the ability to rollback, is a key part of any rollout plan. We must be able to back out changes. It may be that the approach to a rollback is to create a full database backup before implementing the update, but that assumption must be documented and vetted (e.g. the approach of a full backup to support the rollback strategy may not be reasonable in all cases).
This database refactoring issue becomes very tricky when dealing with multiple versions of an application. The transformation of the database schema and data must be done in a defined order. As more and more data is stored, the process consumes more storage and processing resources. This is the ETL side-effect of any system upgrade. Its impact is simply felt more often (e.g. potentially during each iteration) in an agile project.
As part of exploring semantic technology, I am interested in contrasting this to a database that consists of RDF triples. The semantic relationships of data do not change as often (if at all) as the relational constructs. Many times we refactor a relational database as we discover concepts that require one-to-many or many-to-many relationships.
Is an RDF triple-based database easier to refactor than a relational database? Is there something about the use of RDF triples that reduces the likelihood of a multiplicity change leading to a structural change in the data? If so, using RDF as the data format could be a technique that simplifies the development of applications. For now, let’s take a high-level look at a refactoring use case.
(more…)
Tags: agile development, efficient coding, enterprise applications, enterprise systems, Information Systems, linkedin, ontology, refactoring, semantic web, semantics, system integration
Posted in Architecture, Information Systems, Semantic Web, Software Composition, Software Development, Tools and Applications | 1 Comment »
Sunday, May 9th, 2010
Last week I had the pleasure of attending Semantic Arts’ training class entitled, “Designing and Building Business Ontologies.” The course, led by Dave McComb and Simon Robe, provided an excellent introduction to semantic technologies and tools as well as coverage of ontological best practices. I thoroughly enjoyed the 4-day class and achieved my principle goals in attending; namely to understand the semantic web landscape, including technologies such as RDF, RDFS, OWL, SPARQL, as well as the current state of tools and products in this space.
Both Dave and Simon have a deep understanding of this subject area. They also work with clients using this technology so they bring real-world examples of where the technology shines and where it has limitations. I recommend this class to anyone who is seeking to reach a baseline understanding of semantic technologies and ontology strategies.
Why am I so interested in semantic web technology? I am convinced that structuring information such that it can be consumed by systems, in ways more automated than current data storage and association techniques allow, is required in order to achieve any meaningful advancement in the field of information technology (IT). Whether wiring together web services or setting up ETL jobs to create data marts, too much IT energy is wasted on repeatedly integrating data sources; essentially manually wiring together related information in the absence of the computer being able to wire it together autonomously!
(more…)
Tags: efficient coding, enterprise applications, enterprise systems, Information Systems, linkedin, ontology, Public Data, semantic web, semantics, system integration, web services
Posted in Architecture, Information Systems, Public Data, Software Composition, Software Development, Tools and Applications | 1 Comment »
Wednesday, April 14th, 2010
Security is a core interest of mine. I have written and taught about security for many years; consistently keeping our team focused on secure solutions, and am in pursuit of earning the CISSP certification. Some aspects of security are hard to make work effectively and other aspects are fairly simple, having more to do with common sense than technical expertise.
In this latter category I would put full disk encryption. Clearly there are still many companies and individuals who have not embraced this technique. The barrage of news articles describing lost and stolen computers containing sensitive information on unencrypted hard drives makes this point every day.
This leads me to the question of why people don’t use this technology. Is it a lack of information, limitations in the available products or something else? For my part I’ll focus this posting on providing information regarding full disk encryption, based on experience. A future post will describe Blue Slate’s deployment of full disk encryption.
Security focuses on three major concepts, Confidentiality, Integrity and Availability (CIA). These terms apply across the spectrum of potential security-related issues. Whether considering the physical environment, hardware, applications or data, there are techniques to protect the CIA within that domain.
(more…)
Tags: disk encryption, encryption, enterprise systems, full disk encryption, Information Systems, linkedin, mitigation, Security, vulnerability
Posted in Information Systems, Security | No Comments »
Sunday, December 6th, 2009
I have been following the work being done by The Brain Observatory at UCSD to carefully section the brain of patient H.M. The patient, whose identity was protected while he was living, is known as the most studied amnesiac. His amnesia was caused by brain surgery he underwent when he was 27 years old.

Screenshot from the live broadcast of Project H.M.'s brain slicing process
I won’t redocument his history, it is widely available on various websites, a few of which I’ll list at the end of this posting. For me, this study is fascinating in terms of the completely open way the work is being done. The process of sectioning the brain was broadcast in real time on UCSD’s website. The entire process that is being followed is being discussed in an open forum. The data being collected will be freely available. For me this shows the positive way that the web can be leveraged.
I spend so much time in the world of commercial and proprietary software solutions that I sometimes end up with a distorted view of how the web is used. Most of my interactions on the web are in the creation of applications that are owned and controlled by companies whose content is only available to individuals with some sort of financial relationship with the web site owner.
Clearly sites like Wikipedia make meaningful content available at no cost to the user. However, in the case of this work at UCSD, there is an enormous expense in terms of equipment and people in order to collect, store, refine and publish this data. This is truly a gift being offered to those with an interest in this field. I’m sure that other examples exist and perhaps a valuable service would be one that helps to organize such informational sites.
If you are interested in more information about H.M. and the project at UCSD, here are some relevant websites:
Tags: education, Information Systems, Internet, Public Data, science
Posted in Information Systems, Public Data | No Comments »